
In 1998, Larry Page and Sergey Brin were still at Stanford.
They published a paper called The Anatomy of a Large-Scale Hypertextual Web Search Engine. The paper introduced an early version of Google, but the problem it tried to solve was surprisingly simple:
When there are too many web pages, how do you decide which ones matter?
PageRank was one answer. Instead of treating every page as equal, it used the link structure of the web as a signal for importance.
More than two decades later, a similar problem is appearing again.
This time, the system is not only ranking pages in a search result. It is deciding which sources deserve to be cited inside an AI-generated answer.
In AI search, a citation is the source link attached to an answer. It is not just a URL. It is a form of attribution: the model is telling the user which sources it is willing to put behind its response.
A recent Ahrefs study makes this shift visible. Ahrefs analyzed 1.4 million ChatGPT 5.2 prompts and looked at tens of millions of URL retrieval and citation outcomes. The study reported roughly 23.4 million cited URLs, but those citations represented only 49.98% of the URLs ChatGPT retrieved.
In other words: ChatGPT found many candidate pages, but only about half of them received a visible citation.
That is the important part.
AI search is not simply “searching the web.” It is searching, filtering, and then choosing a smaller set of sources to attach to the final answer.
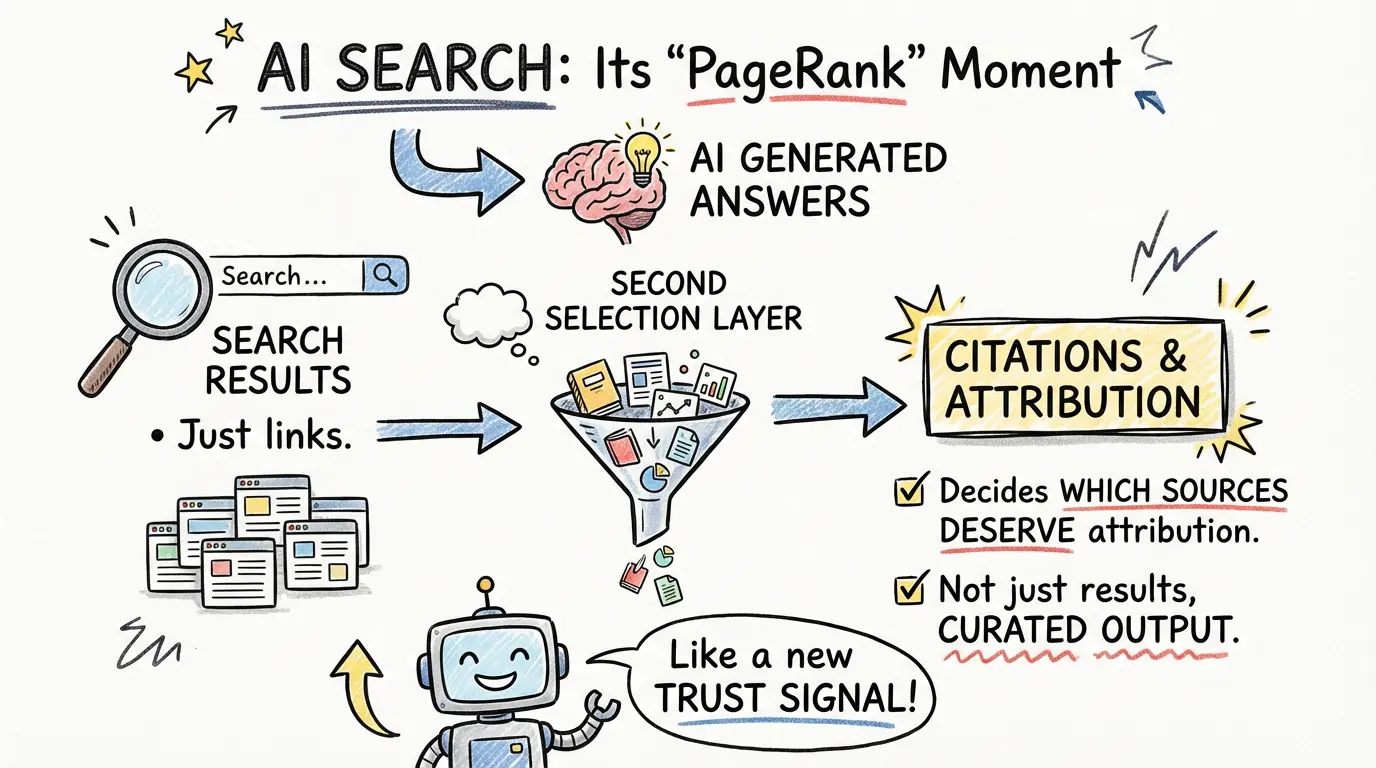
That is why AI search is entering its own PageRank moment.
To be clear, this is an analogy, not a claim about OpenAI’s internal algorithm. We should not say ChatGPT literally uses Google’s PageRank. OpenAI has not said that.
The point is that AI search now faces the same class of problem: when the information space becomes too large and too noisy, retrieval is not enough. The system needs a second layer that decides what is relevant, trustworthy, useful, and worthy of attribution.
In traditional search, that problem became page ranking.
In AI search, it is becoming citation ranking.
Being Found Is Only the Entry Ticket
A common mistake in discussions about AI search is treating “retrieved” and “cited” as the same thing.
They are not.
The Ahrefs data suggests that there is a clear second selection step. In their study, around half of retrieved URLs were cited and around half were not.
That means a page can enter the model’s source pool without making it into the final citation list.
This changes the content problem:
Being found is only the entry ticket. Being cited is the second competition.
In the old search world, content teams cared about crawling, indexing, and ranking. Those still matter. But AI search adds another question: when a model generates an answer, will it choose your page as a source worth showing to the user?
OpenAI’s own documentation reflects this separation in a few ways. Its crawler documentation distinguishes between OAI-SearchBot, which is used for search functionality, and GPTBot, which is used for training data collection. Search visibility and training usage are not the same thing.
The web search API also separates the search action from the final answer annotations that show cited URLs to the user. A system may look at more sources than it ultimately displays.
Put simply:
The source pool is not the same as the citation list.
“The model saw your page” and “the model attributed the answer to your page” are two different outcomes.
That gap is where the new competition begins.
Why AI Needs a Citation-Ranking Layer
This second selection layer is not optional.
The internet is not a clean database. It is a giant candidate pool filled with research, documentation, marketing pages, outdated information, duplicated summaries, forum posts, spam, and AI-generated noise.
If an AI system treated every retrieved page as equally useful, answer quality would collapse.
So it has to filter.
That filtering does not need to be identical to Google’s PageRank. The signals may be different. The objective is different. The user experience is different.
But the underlying problem is familiar:
Given many candidate pages, which ones are relevant enough, credible enough, and clear enough to show as sources?
Traditional search ranking ends in a list of links.
AI citation ranking ends in a generated answer with a few visible sources.
That is a new distribution layer.
In the past, the core question was: can our page appear near the top of search results?
Now there is another question: can our page earn a place inside the answer itself?
For content teams, this is not just a tactical SEO detail. It changes what “authoritative content” means. A useful page is no longer just something people can read. It also has to be something a machine can understand, select, and attribute.
Reddit Shows the Difference Between Being Used and Being Cited
One of the most interesting patterns in the Ahrefs study is Reddit.
Reddit appears to have a large data footprint, but a relatively low citation rate.
At first, that sounds contradictory. If Reddit is retrieved so often, why is it not cited more often?
The answer is that retrieval value and citation value are not the same thing.
Reddit is a massive language mine. It contains real user questions, informal explanations, product complaints, workarounds, community consensus, and lived experience. AI systems may use that material to understand how people talk about a topic.
But Reddit also contains jokes, memes, repetitive questions, low-quality answers, emotional reactions, outdated posts, marketing attempts, and now plenty of AI-generated content.
That makes Reddit useful as context, but not always ideal as a final cited authority.
As a quick check, we ran two Google searches on April 26, 2026:
stardew valley profitstardew valley profit calculator
The screenshots below do not prove that Reddit is cited by large language models. They show something earlier in the chain: Reddit can easily appear in search results and therefore can plausibly enter the candidate source pool.
There is also a detail worth noticing: some of the Reddit-related posts shown in the search results are from 2016 and 2017.
That is the point. High visibility does not automatically mean freshness. High visibility does not automatically mean quality. And high visibility does not automatically mean a page should become a final citation in an AI answer.
This distinction matters for anyone publishing online.
Your ideas may be absorbed into the background context of AI systems. But if those ideas do not live on stable pages with clear titles, clear structure, and attributable conclusions, they may never become visible citations.
Being absorbed is not the same as being credited.
If the Argument Is Unclear, Machines Struggle to Index It
AI search does not necessarily match only against the user’s original query.
To answer a question, a model may break it into smaller intermediate questions. If the user asks, “Why does ChatGPT cite some pages and not others?”, the model may need to reason about source retrieval, source credibility, semantic relevance, title similarity, URL clarity, freshness, and attribution.
That means content does not win just by including the right keywords.
It has to make the answer legible.
A page should make it easy for both humans and machines to understand what question it answers and what claim it is making.
This is where writing craft becomes part of AI visibility.
Titles, URLs, headings, introductions, and conclusions used to be primarily for readers. They still are. But they are also becoming machine-facing signals.
If an article jumps from geopolitics to midlife crisis to AI search to personal growth, a human reader may still sense the emotional thread. A machine may have a much harder time deciding which topic, query, or citation context the page belongs to.
That does not mean every article should become a sterile documentation page. It does mean that if you want a page to become a citable source in AI search, the page needs clearer indexability.
At minimum:
the title should identify the problem;
the URL or slug should carry semantic meaning;
the opening should state the core claim;
the body should develop that claim in a stable structure;
the conclusion should leave behind something quotable and attributable.
The Ahrefs study points in the same direction. It found that cited pages tended to have titles more semantically aligned with prompts and fan-out queries, and that natural-language URL slugs performed better than opaque URLs.
A title does not decide everything. Neither does a slug.
But together, they help the system understand what the page is about.
Freshness Is Not a Free Pass
Another easy oversimplification is freshness.
Yes, fresh content matters. For news, product releases, regulation, prices, and fast-changing technical documentation, freshness can be decisive.
But freshness is not a free pass.
The Stardew Valley screenshots make this visible in a simple way: old Reddit posts from 2016 and 2017 can still appear prominently in search results. They are not new, but they remain visible.
The Ahrefs study also found a more nuanced pattern. ChatGPT tends to prefer newer content overall, but within the same retrieval set, the cited page is not always the newest page. In many cases, more mature and stable pages still win.
That makes sense.
A new page that does not clearly answer the model’s intermediate question may be retrieved and then ignored.
An older page with a clear structure, a strong answer, and credible sourcing may be more useful as a citation.
So the goal is not simply to publish faster.
The goal is to turn a judgment into a durable knowledge unit that can be recognized, reused, and attributed over time.
Citations Do Not Eliminate Hallucinations
There is one more trap: a cited AI answer is not automatically a correct answer.
Citations improve traceability. They do not magically eliminate hallucination.
A model can still misread a source, cite a page that does not support the claim, or attach a plausible-looking reference to a wrong answer.
The Tow Center for Digital Journalism at Columbia Journalism Review ran a useful test of this problem. Researchers selected 200 article excerpts from 20 publishers and asked ChatGPT Search to identify the publisher, publication date, and URL.
The results were poor. In 153 out of 200 cases, ChatGPT Search returned an answer that was partly or completely incorrect. Even more concerning, it rarely admitted uncertainty. It explicitly said it could not answer only seven times.
This is the most dangerous part of AI citations: they can make a wrong answer look sourced.
If you want to test this yourself, use a question with a very clear factual answer. Ask an AI system to answer and cite sources. Then open the cited pages and check whether the page actually supports the specific claim.
Often the problem is not that the link is fake. The link may exist. The problem is that the link does not prove what the AI says it proves.
So two things can be true at the same time:
AI citation ranking will matter more because it affects distribution, visibility, and authority.
AI citations are still not a guarantee of factual correctness.
That is why this topic should not be reduced to “how to get ChatGPT to cite you.”
The deeper question is: as AI systems increasingly filter, summarize, and attribute information on behalf of users, who gets seen, who gets absorbed without credit, and who becomes the authority inside the answer?
What Content Teams Should Do
The content form AI search seems to reward is not just “content.”
It is an attributable knowledge unit.
That means a page should be readable by humans, but also understandable, indexable, selectable, and citable by machines.
For creators, companies, SEO teams, GEO teams, SaaS documentation teams, and product marketers, the practical direction is similar.
First, be clear.
A page should make its core question and answer obvious. The title, opening, headings, and conclusion should all point in the same direction.
Second, be stable.
Durable URLs, topic hubs, documentation pages, long-form essays, and well-maintained help center articles are more useful than scattered social posts that disappear into feeds.
Third, be attributable.
Do not publish only reactions, vibes, or loose commentary. Publish conclusions, frameworks, data, comparisons, definitions, and explanations that can be cited back to you.
This does not mean writing for machines instead of people.
It means building content that can carry authority in both directions: a human reader can trust it, and an AI system can understand why it belongs in a source list.
Short posts are useful for distribution.
But durable authority is usually built through long-form essays, structured documentation, research pages, knowledge bases, and repeated judgment over time.
The New Search Question
For years, the search question was:
Can we be found?
AI search adds a harder question:
Can we be understood, selected, cited, and attributed?
The Ahrefs finding that only about half of retrieved URLs became cited URLs is a useful reminder. Retrieval is only the first step.
The next competition is not just for traffic. It is for attribution inside machine-generated answers.
That is the PageRank moment for AI search.
The most valuable content assets in this environment will not be random posts or keyword-stuffed pages. They will be clear, durable judgment systems that both humans and machines can understand.
References
Ahrefs: Why ChatGPT Cites One Page Over Another (Study of 1.4M Prompts)
OpenAI Docs: Web search / sources and citations
OpenAI Docs: Overview of OpenAI Crawlers
Stanford InfoLab: The PageRank Citation Ranking
Columbia Journalism Review / Tow Center: How ChatGPT Search (Mis)represents Publisher Content